XAMINE
XAMINE stage turns AI strategy into a
portfolio of validated AI pilots
eXAMINE: Validating AI Workflows, Data, Pilots, and Proof-of-Value
Most professional service firms do not fail with AI because they lack motivation and effort.
They fail because they move from enthusiasm to implementation without alignment and examination. Even firm’s that have gone through the ALIGN stage may begin work on AI initiatives that are not feasible or that have poor data or lack ownership.
They identify strategic directions, find promising tools, encourage experimentation, launch scattered pilots, and assume that activity will eventually become value.
Sometimes it does. More often, it creates isolated productivity wins, duplicated tools, inconsistent outputs, uncertain data, and pilots that never become part of the firm’s operating model.
That is why the XAMINE (examine) stage of the CTS AXIS AI Implementation Framework™ exists.
ALIGN answers the strategic question: Where should AI impact business performance?
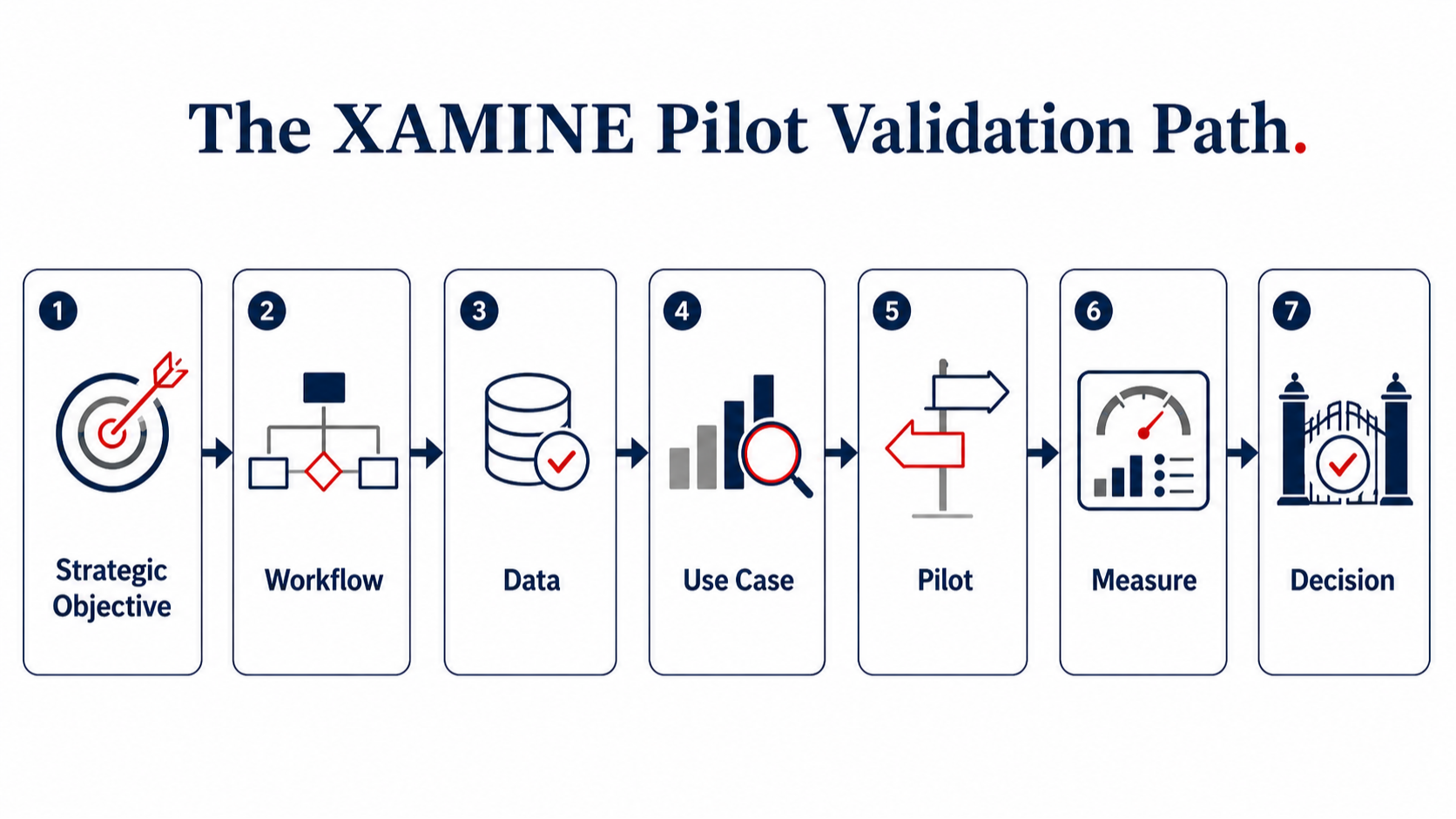
XAMINE answers the operational investment question: Which workflows, data sources, use cases, prompts, assistants, agents, and pilots are valid and consistent enough that they should be tested and implemented?
Without the XAMINE stage, it is easy to be fooled into investing time and resources in an AI initiative that looks great and increases local productivity but fails to help the firm.
A consultant can use AI to summarize calls. A marketer can use AI to draft content. A recruiter can use AI to screen resumes. A partner can use AI to prepare for a sales meeting. These may all look like great demos and be useful. Although helpful, these islands of productivity increase rarely impact a firm’s value.
McKinsey’s 2026 AI measurement research describes this gap directly: many organizations are using AI, but many still struggle to show enterprise-wide EBIT impact. McKinsey argues that AI must be validated, measured and tested with the same rigor as any other capital investment. There must be clear, measurable links between adoption, operational KPIs, strategic outcomes, and financial impact (McKinsey & Company, 2026).
The purpose of XAMINE is to validate and measure the feasibility of the AI initiatives selected in the ALIGN stage.
Quick Answer
What is the XAMINE Stage?
XAMINE is the second stage of the CTS AXIS AI Operating Framework™. This is where professional-service firms examine the elements of an AI initiative to prove they can make a measurable impact.
Those elements are usually workflows, validated data, prioritized AI use cases, test prompts and agents, and proven measurable impact.
XAMINE reduces AI implementation risk by testing whether an AI initiative will consistently make a measurable impact when and where needed.
TL;DR
Take Aways
XAMINE is the AXIS stage where firms examine workflows, data quality, use cases, pilots, prompts, assistants, agents, and proof-of-value before implementation.
The main goal of XAMINE is to prevent implementing AI initiatives that cannot succeed because of invalid workflow assumptions, poor or inconsistent data, or lack of valid measurement.
Applying the XAMINE stage to pilot programs for prompts, assistants, and agents is critical so they can be tested to produce reliable outputs before the firm redesigns or deploys a workflow.
Strong pilots require baselines, success metrics, human review, quality testing, adoption testing, cost tracking, and decision gates.
The outcome of XAMINE is a prioritized, validated AI pilot portfolio ready for disciplined implementation.
Why This Matters
Why the XAMINE Stage Matters: The Gap Between AI Activity and AI Value
AI activity is easy to create. AI activity without an implementation framework often ends up in AI Pilot Purgatory.
In the XAMINE stage you should be testing all the elements necessary to create the business impact you expect.
The outcome from XAMINE should be a ranked list of high-value workflow opportunities, a data-readiness view for each priority workflow, a small portfolio of selected pilots, prompts or agents tested for validity, baseline metrics, Human-In-The-Loop assumptions, and executive decisions for moving to the IMPLEMENT stage.
A successful XAMINE stage will,
Map workflows tied to strategic objectives and economic leverage points
Validate data quality, permissions, freshness, and integration needs
Select use cases with an Impact-Effort Matrix, value-risk-feasibility, or BCG-style use-case prioritization
Pilot prompts, assistants, and agents under realistic workflow conditions
Measure proof-of-value before moving into implementation
Validate results
By the end of XAMINE, your firm should have a clear view of which AI opportunities are ready to implement, which need more preparation, and which should be avoided.
Where XAMINE Fits in the CTS AXIS Framework™
The CTS AXIS AI Operating Framework™ moves through four stages: ALIGN, XAMINE, IMPLEMENT, and SCALE.
ALIGN defines strategic priorities. XAMINE tests operational reality. IMPLEMENT deploys AI into real workflows. SCALE expands, governs, optimizes, and improves AI-enabled operations across the firm.
XAMINE is the checkpoint between strategy and implementation.
This checkpoint is not anti-innovation or a roadblock to progress. Instead, it is a test of how the ALIGN hypothesis works in the real world.
For example, Box reported that it ideated more than 100 AI agents, then systematically narrowed attention toward a smaller set of “Big Bets” designed to produce measurable impact across the business (Box, 2025b).
How Professional Firms Fail with AI in the XAMINE Stage
Firms fail in XAMINE when they confuse activity with evidence.
The most common failure is choosing pilots based on enthusiasm. Someone sees an impressive AI demo and wants to replicate it. The firm launches a pilot because the tool looks exciting rather than because the workflow has strategic value.
This is why you must go through the ALIGN stage prior to selecting pilots for rigorous testing and implementation.
Other causes of failure are,
- Ignoring data readiness
McKinsey & Co. research has found that the second-biggest cause of AI failure in implementation is poor data readiness. Leaders assume the content exists, the data is accurate, and permissions are clear. Later, the team discovers that the data is inconsistent, invalid, or inaccessible. - Poor AI Pilot Selection
Selecting use cases, productivity pilots, or workflows that are not aligned with strategic objectives or are "islands of productivity" - too small to matter. These pilots may succeed technically but fail strategically. They save a few hours for a few people, but they do not affect business performance. - Complex Use Cases
Another cause is selecting workflows that are too complex for your capabilities. These pilots require system integration, change management, governance, and cross-functional coordination before the firm has built its expertise and abilities. - Measuring Only Usage
A common cause of early testing failure is measuring how much people use the AI system. It’s easy to measure but means little with respect to business impact. An AI system may be popular because it is convenient yet still fail to improve operational or financial outcomes.
The purpose of XAMINE is not to make every AI idea look good. It is to reveal which ideas can survive contact with the firm's operating model.
What Successful Firms Do in the XAMINE Stage
High-performing firms treat XAMINE as a management discipline. Follow this numbered checklist to avoid the common causes of failure.
They do not ask teams to “go use AI” and report back with anecdotes. They create a structured process for discovering, scoring, testing, and approving AI opportunities. Here are the priorities you should consider in the XAMINE stage,
- Start with business priorities
Begin with your AI initiatives aligned with strategic objectives, then Big Bets. Identify the objectives and workflows most tied to revenue, margin, client value, risk reduction, or competitive advantage. - Prioritize the portfolio of AI initiatives
You cannot pursue every idea. Balance your list with strategic AI initiatives, Big Bets, quick wins, and meaningful workflow improvements. - Map workflows before choosing tools
This reveals bottlenecks, handoffs, data dependencies, review points, and rework loops. - Identify AI pilots that impact selected workflows
Use a combination of the methods described below to select your best pilot opportunities. - Validate data and content
These are the data AI needs. Identify where the information lives, who owns it, it’s reliability, and permission levels. - Define success metrics
Before starting your AI pilot know the definition of success.. - Assign accountable owners
Business leaders own the “why” and “what.” AI development teams support the “how.” - Define pilot improvements
Make decisions at the end of each pilot about what should be changed, improved, or removed. - Loop back
Loop back and modify pilots as needed or stop.
This is a similar step-by-step process to the one Box describes in its AI-first transformation work: functional leaders own transformation for their teams within a centrally defined strategy and guardrails, with specialized teams that help convert ideas into agentic workflows (Box, 2025a).
That model is important because it avoids two common issues.
- If AI is completely centralized, departments may feel slowed down or disconnected from their own workflows. This is one of the reasons we rely heavily on department- or functional-team AI Implementation Workshops.
- If AI is completely decentralized, firms risk duplication, inconsistency, and weak governance. A more Iuccessful approach is to select one department or team, such as marketing, to serve as a successful, well-coordinated example of success. This success then serves as an example for other coordinated implementations.
For mid-sized professional service firms, this does not require a large AI office. It requires a simple operating system,
- The leadership team defines strategic objectives and priorities.
- Department leaders submit workflow opportunities.
- A small cross-functional team scores and selects pilots.
- Selected pilots go through the Xamine stage.
- Executives review the cases and results.
- Only validated and approved pilots move into the IMPLEMENT stage.
Your processes may be lighter than what is listed here, but you must XAMINE and validate key elements prior to moving to the IMPLEMENT stage.
Identifying Workflows that Matter
The workflow is the most important foundation of an XAMINE validation.
A use case is only valuable if it improves a workflow that matters. A tool is only valuable if it fits the workflow. A prompt is only valuable if it improves a task inside the workflow. An agent is only valuable if it can perform or coordinate steps in the workflow with acceptable quality, risk, and oversight.
For a consulting firm, the workflow might be client discovery, market research, proposal development, project delivery, or knowledge reuse.
For a marketing agency, it might be audience research, campaign planning, content production, distribution, conversion analysis, or client reporting.
For an accounting or advisory firm, it might be document review, client onboarding, monthly close, advisory reporting, compliance support, or anomaly detection.
The XAMINE stage begins by mapping the workflow as it exists today.
That mapping should identify the inputs, handoffs, decision points, bottlenecks, rework loops, systems, data sources, human review points, and outputs. It should also identify where the workflow affects measurable business outcomes.
For example, a proposal workflow may affect win rate, average deal size, partner review time, margin quality, and speed to submit.
A research workflow may affect delivery speed, insight quality, analyst utilization, and reuse of intellectual capital.
A recruiting workflow may affect time-to-shortlist, candidate quality, hiring manager satisfaction, and recruiter capacity.
The goal is not to document every step forever. The goal is to understand where AI can change performance.
A good workflow examination asks,
- Where does work slow down?
- Where do experts repeat low-value tasks?
- Where is knowledge hard to find?
- Where does quality vary?
- Where does rework occur?
- Where do handoffs fail?
- Where does data get copied, cleaned, or reinterpreted?
- Where could AI assist, recommend, automate, or orchestrate?
This examination protects firms from automating worthless processes or noise in the system.
Use-Case Selection: Separating Interesting Ideas from Valuable AI Opportunities
Use-case selection is where XAMINE becomes a management discipline.
Most firms will have more AI ideas than they can responsibly test. That is a good problem. But it becomes dangerous when every idea receives equal attention.
The best use cases are not always the flashiest. They are the ones with the strongest combination of strategic relevance, workflow value, repeatability, data readiness, feasibility, risk control, and measurable impact.
For professional service firms, the executive use-case filter should include,
- Strategic alignment: Does the use case support a strategic objective, Big Bet, KPI, or economic leverage point?
- Workflow value: Does it improve a workflow that affects growth, margin, quality, speed, capacity, risk, or client value?
- Frequency: Does the workflow happen often enough for improvement to matter?
- Pain level: Is there a real bottleneck, cost, delay, quality issue, or frustration?
- Data readiness: Are the required inputs usable, accessible, and safe?
- Feasibility: Can the firm test this in a limited pilot without major disruption?
- Risk: What is the consequence of a wrong output?
- Measurement: Can the firm define a baseline and prove improvement?
- Scalability: If the pilot works, can the use case become part of a repeatable operating workflow?

Selecting Your Pilot Portfolio: Strategic Workflows, Big Bets, and Quick Wins
XAMINE should not rely on just one prioritization tool for choosing pilots, assistants, or Big Bets.
The easy-to-use Impact-Effort Matrix helps sort quick wins from more difficult opportunities. The Impact-Effort Matrix ranks each potential pilot project on its impact to the firm and its ease of implementation, and then it is placed on an Impact-Effort Matrix with four quadrants,
- High Impact, High Effort: Major Projects/Big Bets
- High Impact, Low Effort: Quick Wins
- Low Impact, Low Effort: Low Priorities
- Low Impact, High Effort: Avoid
While the Impact-Effort Matrix is easy to create and to develop team consensus around, it is usually used only as a first-pass filter.
Most firms will want to use an Impact-Effort Matrix for a first pass to eliminate the majority of potential pilots. The top 12 to 15 selected from this matrix should be carried over to a selection-style matrix with additional weighting factors.
A selection matrix with more factors adds a deeper test of value potential, feasibility, data readiness, cost, complexity, time to value, and workflow transformation. A value-risk-feasibility score helps executives judge whether a pilot is attractive enough to justify risk and resource commitment.
For AI initiatives, the firm should balance three types of pilots.
- The first category is quick wins. These are low-risk, focused pilots that save time or improve quality in a repeatable task. They build adoption and confidence. If you do not have in-house expertise or are not working with a consulting firm, like Critical to Success, you may want your AI development team to develop 3 or 4 of these simple initiatives to build their skills.
- The second category is strategically aligned workflow pilots. Firms should start with no more than 3 of these pilots. These connect directly to objectives such as growth, margin, utilization rates, client retention, delivery speed, or quality. These can be critical to your firm’s success – develop these projects with highly experienced in-house AI Heroes or AI consulting firms like Critical to Success.
- The third category is transformational Big Bets. These explore future operating capabilities that may create durable competitive advantage.
Do not let your AI portfolio overinvest in random productivity initiatives. Productivity gains are useful, but if they are not aligned with strategic workflows, they can create “islands of productivity” that make individuals faster without making the firm stronger.
A practical pilot portfolio might include one or two quick wins in a learning phase, three or four strategic workflow pilots, and one exploratory Big Bet. This keeps your firm moving without becoming overwhelmed.
Data Examination and Data Alignment: Testing Whether the Workflow Has Usable Inputs
Data examination is not a technical afterthought. It is one of the most important tests in XAMINE.
AI systems require usable inputs. Those inputs may be structured data, such as CRM records, financial data, project data, or campaign metrics. They may also be unstructured content, such as proposals, contracts, research reports, meeting transcripts, emails, slide decks, policies, or client documents.
Professional service firms often have valuable knowledge, but it is not always AI-ready.
The data may exist but is poorly organized. It may be accurate in one system and outdated in another. It may be useful but not accessible for broad access. It may include confidential client information. It may be inconsistent across teams. It may require context that only senior experts understand.
All of those bumps and inconsistencies must be managed and accounted for.
In XAMINE, data examination should answer five practical questions.
- Is the data available? Does the required data or content exist?
- Is the quality sufficient? Is it accurate, current, complete, and reliable enough for the workflow?
- Is the data accessible? Can the AI system access it without violating permissions, confidentiality, or client obligations?
- Is it integrated? Does the workflow require data from multiple systems that must be reconciled?
- What are the consequences of bad data? What happens if the AI uses the wrong data or produces an incorrect output?
For AI workflow pilots, data readiness also means data alignment. The workflow’s data must be consistent with related systems, definitions, permissions, client records, project records, and performance metrics. If related datasets disagree, AI may create confusion rather than improve the workflow.
AI Piloting: Testing AI Validity Before Deployment
This is one of the most important parts of XAMINE.
Before a firm redesigns a workflow around AI, it should test whether the prompt, assistant, or agent can perform reliably under realistic conditions. This is not just prompt engineering. It is operational validation.
What works in the “lab” may not work in “the real world.”
A prompt pilot tests whether a structured prompt can improve a defined task. Examples include client research synthesis, proposal strategy, meeting preparation, campaign planning, competitive analysis, or report drafting.
An assistant pilot tests whether a reusable AI assistant can support a recurring role or workflow. Examples include a proposal strategist assistant, market research assistant, recruiting screener, campaign planner, client discovery assistant, or project reporting assistant.
An agent pilot tests whether AI can complete or coordinate a multi-step workflow. Examples include an RFP response agent, account research agent, recruiting intake agent, content repurposing agent, or client onboarding agent.
Each type of pilot should be tested for output quality, consistency, accuracy, hallucination risk, data dependency, time savings, human review burden, user adoption, cost per useful output, and workflow fit.
A prompt that performs well once may not perform well across 25 different client scenarios. An assistant may save time for an expert but confuse junior staff. An agent may work on clean examples but fail when source documents are messy, missing, contradictory, or confidential.
The firm should run multiple cases, compare AI outputs against human-created or human-approved benchmarks, track how much editing is required, identify failure modes, and ask users whether the AI output actually improves the workflow or simply creates another review burden.
Agent pilots require special care. Because agents may take multiple steps, the firm must define inputs, allowed actions, escalation rules, handoff points, review requirements, and stop conditions. An agent should not be judged only by whether it completes a task. It should be judged by whether it completes the right steps, uses the right information, follows the right rules, and produces outputs humans can trust.
Testing agents can be a significant jump in complexity over testing prompts.
Critical to Success believes strongly in Boston Consulting Groups recommendation to break agentic workflows into defined tasks. This makes it easier to test and identify problems (Boston Consulting Group, n.d.). We do this as AI to ROI Sprints within our AI Implementation Workshops.
AI Implementation Workshops:
Our AI Implementation Workshops are built to follow BCG's recommendations. For example, in the marketing department workshop, end-to-end workflows are segmented into two-week AI to ROI Sprints. Each sprint contains groups of tasks that complete a group of work tasks. Most groups end with a human-in-the-loop checkpoint before the next AI system or Sprint begins. In the last stage of the workshop, the results from all AI to ROI Sprints are integrated.
Measurement Validation: Making Sure the Metrics Are Real
Measurement validation is different from measurement selection.
A team may choose metrics, but XAMINE must determine whether those metrics are credible and accessible.
For example, “time saved” is useful only if the firm knows the original cycle time and measures the new cycle time honestly. “Quality improved” is useful only if there is a quality rubric. “Adoption increased” is useful only if usage connects to a meaningful workflow.
McKinsey’s “five-layer AI measurement framework” is helpful in the XAMINE stage because it separates different levels of AI value: technical performance, user adoption and engagement, operational KPIs, strategic outcomes, and financial impact (McKinsey & Company, 2026).
A prompt pilot may focus on technical quality and user adoption. An AI assistant pilot may focus on adoption, cycle time, and quality. An agent pilot may need operational KPIs and cost-to-serve metrics. A strategic AI workflow should impact a bottom-line metric. A Big Bet may include strategic outcomes and early indicators before full financial impact appears.
Without validated metrics, pilots become stories. With validated metrics, they become investment evidence.
Testing Pilots for Proof-of-Value
Decide up front what a successful pilot looks like.
A strong pilot test includes eight elements,
- It defines the current baseline. How long does the workflow take today? How many people are involved? What is the error rate? How much rework occurs? What does quality look like? What cost or delay does the workflow create?
- It defines the target improvement. The target may be faster cycle time, fewer errors, better quality, higher throughput, improved conversion, reduced cost, or stronger client satisfaction.
- It defines the test group. Who will use the AI-enabled workflow? How many cases will be tested? What types of cases will be included?
- It defines the human review model. Will every output be reviewed? Will experts review samples? Will AI handle low-risk work while humans review exceptions?
- It defines output scoring. Outputs should be evaluated for accuracy, completeness, clarity, usefulness, brand or client fit, compliance, and required editing.
- It tracks user behavior. Are users actually using the prompt, assistant, or agent? Do they trust it? Do they override it? Do they abandon it?
- It tracks cost and effort. A pilot that saves drafting time but doubles review time may not be a true improvement.
- It ends with a decision gate. The pilot should move to one of five decisions:
Stop, Revise, Retest, Implement, or Reserve for later scaling.
McKinsey & Co. recommends that companies breaking out of the pilot trap use clear metrics, attribution methods such as A/B testing or staggered deployment, review cadences, stage gates, and evidence packs that track benefits and total cost of ownership (McKinsey & Company, 2026).
Human + AI Review Models: Determining the Right Level of Oversight
XAMINE should also include a human review model.
Not every AI workflow requires the same oversight. Some outputs can be lightly reviewed. Some require expert approval. Some require exception handling. Some should remain human-led with AI support only.
The right review model depends on risk, complexity, client exposure, regulation, brand sensitivity, and the cost of errors. For example,
- A low-risk internal research summary may need light review.
- A client-facing proposal section may need senior review.
- A recruiting screen may need bias controls.
- A financial advisory output may need expert approval.
- A client recommendation may require full human ownership.
The key question is not, “Can AI do this?” It is, “What level of human judgment is required for this workflow to be safe, useful, and trusted?”
It is key that your “Human-In-The-Loop” should know what is expected of them, the detail and the degree of judgement they need to apply to AI results. The XAMINE state is where you can identify this.
XAMINE should identify human + AI model before implementation,
- AI drafts, human edits.
- AI recommends, human decides.
- AI completes low-risk work, human reviews exceptions.
- AI monitors, human investigates.
- AI prepares, human presents.
- AI assists, human remains fully accountable.
This avoids both underuse and overtrust.
Executive Decision Gates: Stop, Refine, or Implement
Every pilot should end with a decision. The stopping point needs to be clear.
Without decision gates, pilots linger. Teams continue improving them without knowing whether they matter. Executives lose visibility. AI activity accumulates without operating discipline.
The XAMINE decision gate should produce one of five outcomes.
- Stop if the pilot does not create enough value, is too risky, lacks adoption, or depends on weak data.
- Refine if the concept is valid but the prompt, workflow, data, or review model needs improvement.
- Retest if the pilot produced mixed evidence or was tested under conditions too narrow to support a decision.
- Implement if the pilot proves enough value to move into operational deployment.
- Hold for later in the SCALE stage if the pilot is strategically important but requires broader systems, governance, data integration, or cross-functional adoption before expansion.
The decision gate should be based on evidence, not politics. A senior sponsor may like a pilot. A team may enjoy using it. A vendor may show impressive demos. None of that is enough.
XAMINE should ask: Did it improve a workflow that matters, with acceptable risk, measurable value, and a realistic path to implementation?
If yes, it moves forward. If not, it changes or stops.
How the XAMINE Stage Prepares for the IMPLEMENT Stage
XAMINE prepares the firm for IMPLEMENT by reducing uncertainty.
By the end of XAMINE, the firm should know which workflows matter, which data sources are ready, which use cases deserve attention, which prompts or agents are valid enough, which pilots have proof-of-value, which review models are required, and which executives own outcomes.
This means IMPLEMENT does not begin with hopes, wishes, and guesswork. It begins with evidence.
A firm that skips XAMINE may enter implementation with excitement, but weak operating clarity. A firm that completes XAMINE enters with a prioritized pilot portfolio, tested AI assets, validated metrics, clearer data requirements, known risks, and stronger executive confidence.
That is the difference between AI experimentation and AI implementation.
XAMINE does not eliminate risk. It makes risk visible before the firm commits. It does not slow down AI adoption. It increases the odds that adoption produces measurable value.
FAQ
Frequently Asked Questions
What is the XAMINE stage of the CTS AXIS Framework?
Why is XAMINE important before AI implementation?
How should firms select AI use cases?
Why are prompt and agent pilots important?
What should an AI pilot test measure?
How does XAMINE prevent Pilot Purgatory?
How does XAMINE prepare for IMPLEMENT?
About the Author
Ron Person is the founder of Critical to Success (CTS) and the creator of the AXIS AI Implementation Framework™. Ron guides professional service firms in using the AXIS AI Implementation Frameworktm to align AI with strategic objectives, validate and implement AI in departments and functional teams, and then SCALE AI for business impact.
He brings more than 30 years of consulting experience with Fortune 1000 and Global 1000 firms. His experience includes business strategy, digital marketing, data analytics, process improvement, and technology implementation.
Ron has authored 27 books with almost 3 million copies in print and has served as an adjunct professor in the Executive Extension at University California, Berkeley. He has an MBA Marketing/Finance, MS Physics, Black Belt Six Sigma, and is certified in Balanced Scorecard.


About Critical to Success
Critical to Success helps professional service firms implement AI to impact strategic objectives, Big Bets for the future, and workflow performance. The firm works with consultants, marketers, accountants, financial service firms, architecture firms, engineering firms, and other knowledge-based businesses that want to measurably improve strategic objectives, workflow performance, productivity, and client value.
Critical to Success developed the CTS AXIS AI Implementation Frameworktm to help firms move from random AI experimentation to structure implementation. The framework guides firms through four stages of adopting AI: Align, eXamine, Implement, and Scale.
Critical to Success provides AI advisory services, AI implementation workshops tailored to departments and functional teams, executive education, AI implementation playbooks, and development of AI solutions.
This article is part of the Critical to Success AI implementation library and is designed to help leaders move from AI experimentation to structured, measurable, and scalable AI adoption.
Editorial Note
This article is part of the Critical to Success AI implementation library. It is written for professional service firm leaders who need practical guidance on AI strategy, workflow improvement, governance, adoption, and measurable business value. Content is periodically reviewed and updated to reflect changes in AI tools, implementation practices, and the needs of professional service firms.
SOURCES
Boston Consulting Group. (2023). Biopharma’s path to value with generative AI (BCG).
https://www.bcg.com/publications/2023/biopharma-path-to-value-with-generative-ai
Boston Consulting Group. (n.d.). AI agents: What they are and their business impact (BCG).
https://www.bcg.com/capabilities/artificial-intelligence/ai-agents
Box. (2025a). AI-first transformation: Box’s principles, strategy, and execution framework (Box Blog). https://blog.box.com/ai-first-part-1
Box. (2025b). From 100 agents to strategic big bets: How Box found focus in AI deployment (Box Blog). https://blog.box.com/ai-first-part-2
Box. (2026). How AI transformation really happens (Box Blog).
https://blog.box.com/coo-ai-transformation-lessons
McKinsey & Company. (2026a). From promise to impact: How companies can measure—and realize—the full value of AI (QuantumBlack, AI by McKinsey).
https://www.mckinsey.com/capabilities/quantumblack/our-insights/from-promise-to-impact-how-companies-can-measure-and-realize-the-full-value-of-ai
McKinsey & Company. (2026b). The AI transformation manifesto (McKinsey Quarterly).
https://www.mckinsey.com/capabilities/tech-and-ai/our-insights/the-ai-transformation-manifesto
